

速递|Meta豪赌AI,即将发布全能模型Llama 4
速递|Meta豪赌AI,即将发布全能模型Llama 4马克·扎克伯格今年正在提升 Meta 人工智能的语音功能,准备从这项快速发展技术中创收。
来自主题: AI资讯
10932 点击 2025-03-10 14:37
马克·扎克伯格今年正在提升 Meta 人工智能的语音功能,准备从这项快速发展技术中创收。

虽然 Qwen「天生」就会检查自己的答案并修正错误。但找到原理之后,我们也能让 Llama 学会自我改进。
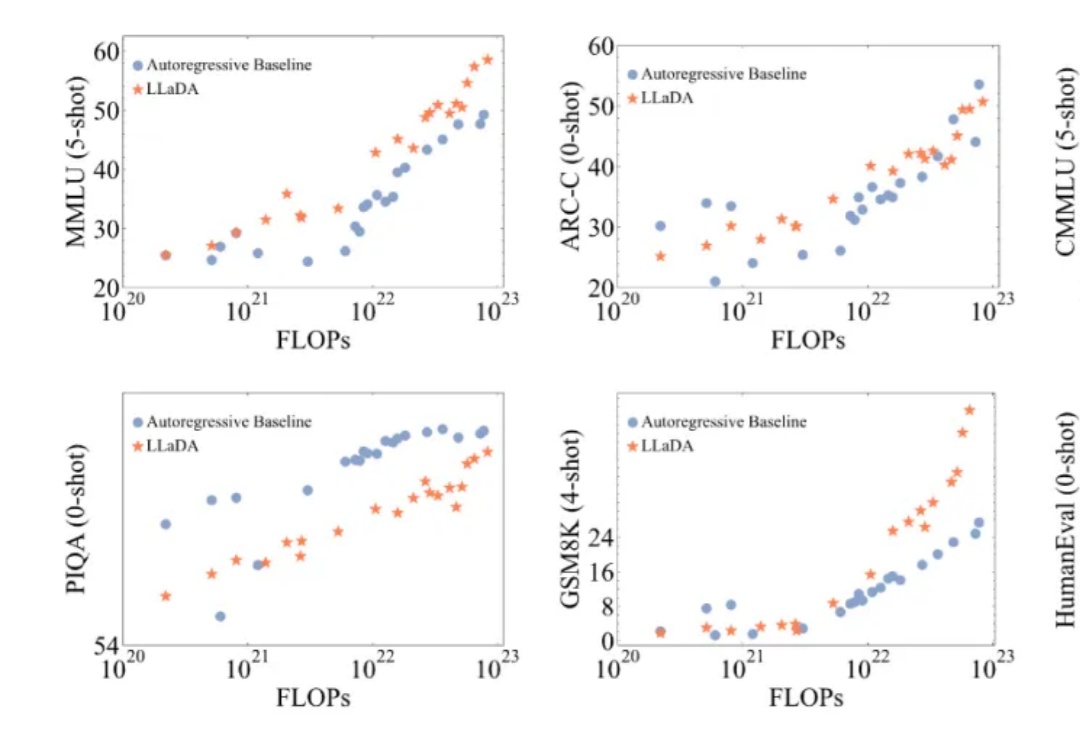
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。

2024年11月,艾伦人工智能研究所(Ai2)推出了Tülu 3 8B和70B,在性能上超越了同等参数的Llama 3.1 Instruct版本,并在长达82页的论文中公布其训练细节,训练数据、代码、测试基准一应俱全。
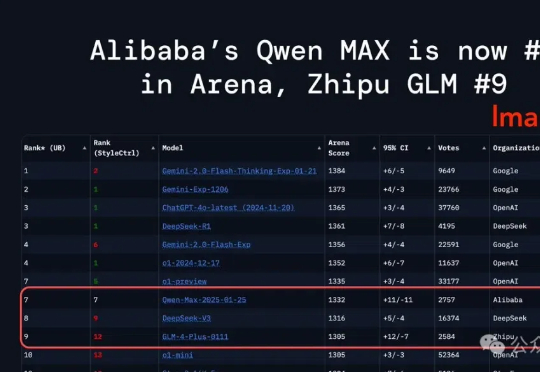
刚刚,大模型竞技场榜单上再添一款国产模型——来自阿里,Qwen2.5-Max,超越了DeepSeek-V3,以总分1332的成绩位列总榜第七。同时还一举超越Claude 3.5 Sonnet、Llama 3.1 405B等模型。

Meta这次真的坐不住了,计划在AI上继续加码!匿名员工爆料,黑马DeepSeek的出现,让Llama 4还未发布就已经落后,Meta慌了。

「工程师正在疯狂地分析 DeepSeek,试图从中复制任何可能的东西。」DeepSeek 开源大模型的阳谋,切切实实震撼着美国 AI 公司。最先陷入恐慌的,似乎是同样推崇开源的 Meta。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。

DeepSeek-v3大模型横空出世,以1/11算力训练出超过Llama 3的开源模型,震撼了整个AI圈。